I run a 3-node Kubernetes cluster at home for media, automation, and learning. Recently I built an autonomous AI agent that lives inside the cluster, reviews pull requests, diagnoses alerts, fixes issues, and lets me chat with my infrastructure through a web UI. This post covers the full setup — the cluster itself, the GitOps workflow, and the agent that operates it.
The hardware is three Minisforum MS-01 mini PCs, each with a 13th-gen Intel CPU, 16 GB DDR5 RAM, and a 1 TB Samsung 990 Pro NVMe. The three nodes are connected in a Thunderbolt 4 mesh - each MS-01 has two TB4 ports, so every node has a direct 40 Gbps link to the other two. They run Talos Linux - a minimal, immutable OS purpose-built for Kubernetes. No SSH, no shell, no package manager. You manage it entirely through an API.
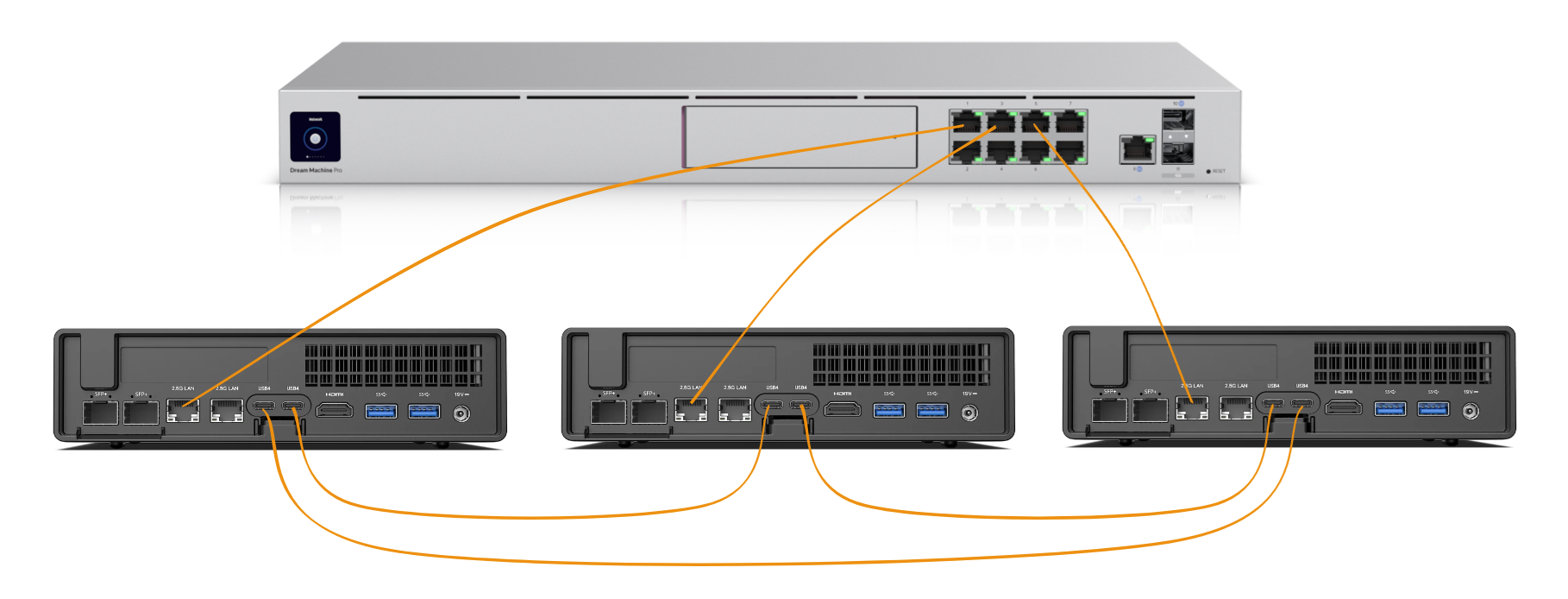
All three nodes serve as both control plane and worker. There are no dedicated workers - every node runs the full Kubernetes stack plus application workloads.
The nodes sit on a dedicated SERVERS VLAN (192.168.42.0/24) behind a UniFi Dream Machine Pro. Key IPs are reserved:
- .10 for the Kubernetes API
- .11 for internal DNS (k8s-gateway)
- .12/.13 for internal/external ingress (Envoy Gateway)
- .14 for AdGuard Home (DNS for the whole network)
- .100-.102 for the three nodes
Cilium handles CNI and L2 announcements. Envoy Gateway provides ingress with automatic TLS via cert-manager and Let’s Encrypt. External access goes through a Cloudflare Tunnel - nothing is exposed directly to the internet.
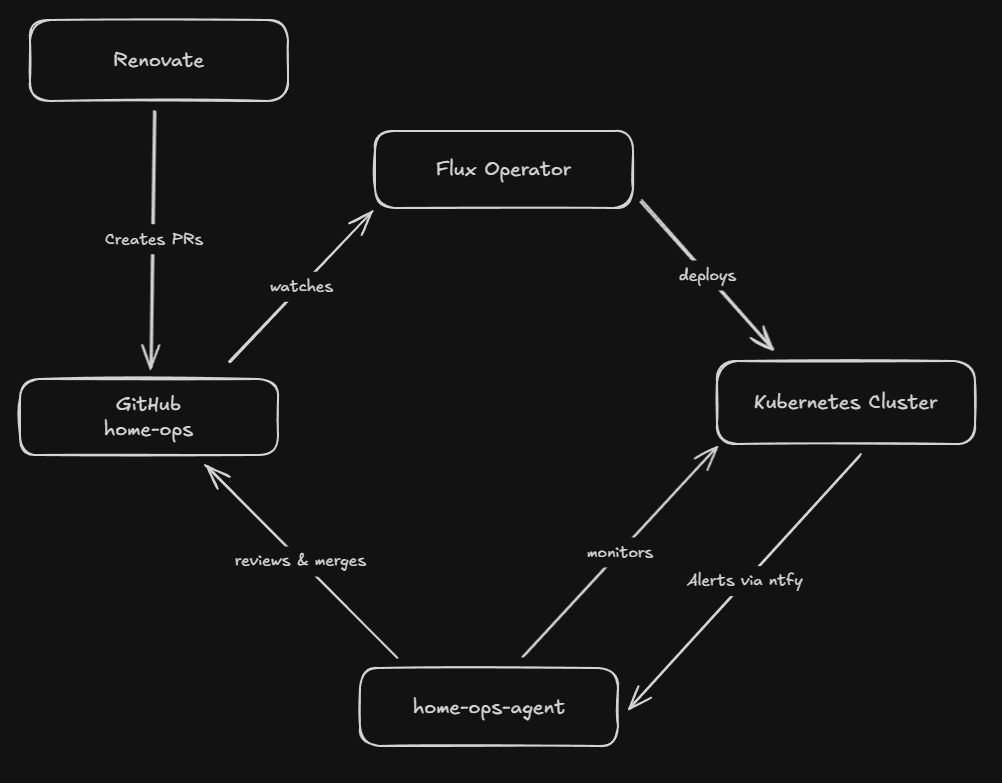
Everything in the cluster is defined as code in a single GitHub repository. The Flux Operator watches the repo and reconciles the desired state continuously. Push a change to main, and Flux deploys it within minutes.
Every application follows the same pattern using the bjw-s app-template Helm chart:
kubernetes/apps/<namespace>/<app>/├── ks.yaml # Flux Kustomization└── app/├── kustomization.yaml├── ocirepository.yaml├── helmrelease.yaml # The actual app config└── secret.sops.yaml # Encrypted secrets
Secrets are encrypted with SOPS using age keys - they live safely in the git repo, encrypted at rest, and Flux decrypts them at deploy time.
Renovate runs on a schedule, scanning the repo for outdated container images, Helm charts, and GitHub Actions. It creates pull requests automatically - sometimes 5-10 per week. Each PR runs through flux-local validation in CI to catch manifest errors before merging.
This works well, but reviewing and merging these PRs manually is tedious. Most are straightforward patch bumps that just need someone to check CI is green and click merge. That’s what led me to build the agent.
The cluster hosts a complete home infrastructure stack:
Monitoring: Prometheus, Grafana, Loki, Alloy, ntfy, Gatus, smartctl-exporter, Unpoller
Automation & AI: n8n, Qdrant (vector DB), crawl4ai, and the home-ops-agent
Infrastructure: AdGuard Home, k8s-gateway, Cloudflare Tunnel, external-dns, Envoy Gateway, cert-manager, Authentik (SSO)
Database: CloudNativePG (PostgreSQL 16 with pgvecto.rs), Valkey (Redis-compatible cache)
Media: Jellyfin, Sonarr, Radarr, Prowlarr, Bazarr, qBittorrent, Recyclarr, Seerr, FlareSolverr
Backup: Volsync replicates PVCs to Cloudflare R2 for off-site backup
Storage: local-path-provisioner for now - each PVC is pinned to the node where it was created. A NAS upgrade with democratic-csi is planned for the future.
The GitOps setup is great for deployment, but day-to-day operations still required manual work:
- PR review fatigue - Renovate creates PRs constantly. Most are safe patch bumps, but you still need to check each one, verify CI passes, and merge manually.
- Alert noise - Prometheus fires alerts through Alertmanager to ntfy on my phone. I get a notification that says something like “KubePodCrashLooping” - but then I need to SSH in (well, kubectl in), check logs, figure out what happened, and decide what to do.
- Context switching - When something breaks at 10 PM, I need to open a terminal, remember which namespace the app is in, check the right logs, and piece together what went wrong. It’s a lot of cognitive load for a home lab.
I wanted something that could handle the routine stuff autonomously and give me better information when it couldn’t.
The home-ops-agent is a Python application that runs inside the cluster as a regular deployment. It uses the Anthropic Claude API to reason about the cluster and take actions through a set of tools.
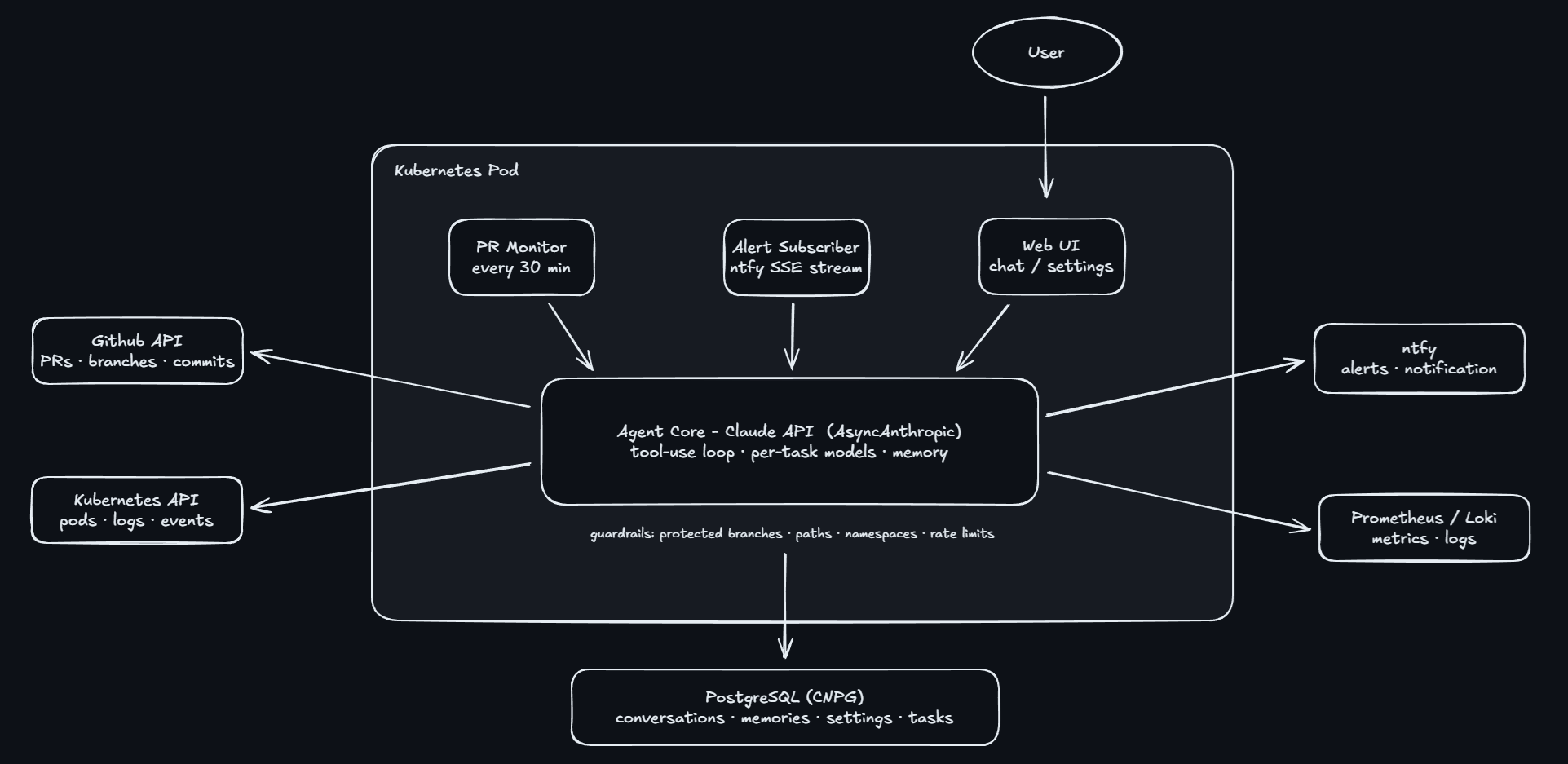
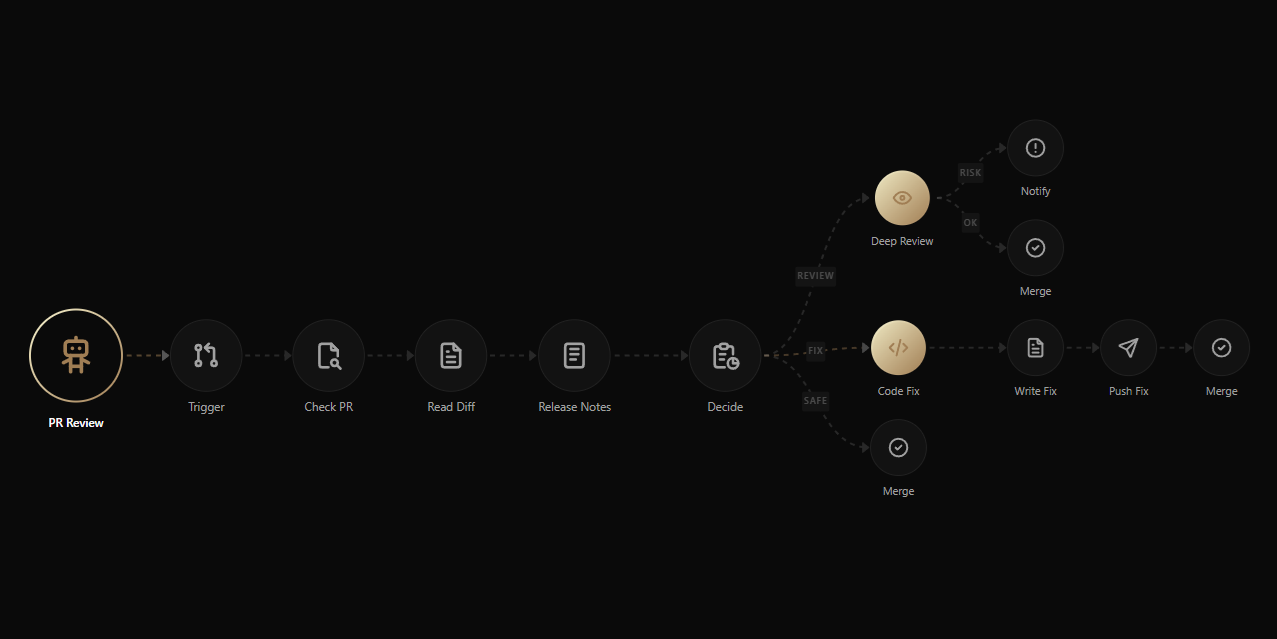
The agent has three main operating modes:
PR Monitor - Every 30 minutes, it checks GitHub for open pull requests. The monitor has a 4-tier mode that controls how much autonomy it has:
- Comment Only - Reviews PRs and posts comments, but never merges anything.
- Auto-Merge Patch - Automatically merges safe patch bumps after CI passes. Anything bigger gets a comment.
- Auto-Merge Minor - Same as above, but also auto-merges minor version bumps.
- Fully Autonomous - Handles everything. When it encounters a high-risk PR (Cilium upgrades, Flux changes, cert-manager), it escalates to Opus for a deep review before deciding whether to merge or flag it for me.
For each PR, the agent reads the diff, checks CI status, and assesses risk. Simple patch bumps flow through quickly. PRs that need code fixes get handed to the Code Fix agent, which commits the fix, waits for CI to pass, and then merges. High-risk PRs in Fully Autonomous mode get a thorough second opinion from Opus before any action is taken.
Alert Subscriber - It maintains a persistent SSE connection to ntfy, listening to the alertmanager and gatus topics. When an alert fires, it goes through a two-stage pipeline: first, Haiku does a quick triage - checks pod status, reads logs, queries metrics, and decides whether this actually needs fixing or is just noise. If the alert needs action, it escalates to Sonnet, which investigates deeper and applies a fix (restart a stuck pod, reconcile a Flux resource, commit a manifest change). After fixing, the Code Fix agent waits for CI to pass before merging. If the alert is informational or self-resolving, the triage stage handles it alone - no expensive model call needed.
Interactive Chat - A web UI where I can ask questions like “What pods are running in the media namespace?” or “Why is Sonarr using so much memory?” The agent uses its tools to get live data and responds with actual cluster state, not memorized information.
The agent has a modular skills system that extends what it can do. Built-in skills (Kubernetes, GitHub, ntfy) are always available - they’re the core tools for cluster operations. Optional skills can be enabled or disabled from the settings page:
- Prometheus - Query metrics directly, check alert rules, inspect targets
- Loki - Search and filter logs across namespaces
- Flux CD - Reconcile sources, check Kustomization status, suspend/resume resources
This keeps the agent’s context lean by default. If I’m debugging a log issue, I enable the Loki skill. If I don’t need it, it stays off and doesn’t clutter the tool list.
Different tasks have different complexity, and Claude models have very different costs. The agent uses cheaper models for simple tasks:
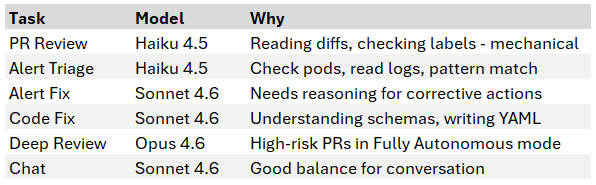
All models are configurable through the settings UI. I can bump Code Fix to Opus for a tricky migration, then switch it back.
The agent extracts key facts from conversations and remembers them across future interactions. After each chat, Haiku analyzes the conversation and saves structural knowledge - things like “local-path-provisioner PVCs are pinned to their creation node via PV nodeAffinity” or “user prefers ntfy notifications for all restarts.”
This means the agent learns about my specific cluster over time. It won’t suggest adding a nodeSelector to fix PVC scheduling if it already knows the provisioner handles that automatically.
Memories are stored in PostgreSQL and viewable in the UI. I can delete incorrect ones or let them accumulate naturally through conversations.
Giving an AI agent access to your Kubernetes cluster and GitHub repo requires careful constraints. All safety measures are enforced at the code level - they cannot be bypassed by prompt injection or creative reasoning:
- Protected branches - Cannot commit directly to main or master
- Branch naming - Can only create branches starting with fix/, feat/, or agent/
- Path restrictions - Can only modify files under kubernetes/apps/
- Protected namespaces - Cannot restart or delete pods in kube-system, flux-system, or cert-manager
- RBAC - The ServiceAccount has minimal permissions: read most things, patch deployments (for restarts), delete pods (for recreation). No create, no namespace modification.
- Rate limiting - Maximum 3 PR reviews per cycle to prevent runaway token usage
- Duplicate protection - Won’t re-review a PR unless the head SHA changes
- Kill switch - One button in the UI to disable all autonomous activity immediately
When a PR comes in, the agent evaluates it and lands on one of four outcomes:
- Safe - CI passes, risk is low, the change is straightforward. The agent merges it directly (if the PR mode allows auto-merge).
- Needs Fix - The diff has an issue (missing field, wrong value, breaking schema change). The Code Fix agent creates a corrective commit on the PR branch, waits for CI to pass, then merges.
- Needs Review - High-risk component in Fully Autonomous mode. The agent escalates to Opus for a deep review. Opus either confirms it’s safe to merge or flags it for manual attention with a detailed explanation.
- Comment Only - In lower autonomy modes, the agent posts its analysis as a PR comment and leaves the merge decision to me.
The Code Fix agent deserves its own mention. When it identifies a problem - whether from a PR review or an alert investigation - it creates a branch (fix/, feat/, or agent/ prefix), commits the corrected manifest, opens a PR, and then monitors CI. Once CI passes, it merges. The whole cycle happens without intervention.
It never pushes directly to main. Every change goes through the normal PR and CI process.
The web UI is built with Next.js 16, shadcn/ui (Base UI), and TypeScript. It has four main sections:
Dashboard - The landing page shows an agent flow visualization built with React Flow and dagre auto-layout. You can see the full pipeline - PR Monitor and Alert Subscriber feeding into their sub-agents, with connections showing how work flows between them. A status bar at the top shows the connection status, the current PR mode as a badge, and a countdown timer to the next PR check cycle. Two agent cards (PR Review and Alert) display which sub-agent models are active. Clicking an agent card opens a slide-in panel where you can edit its system prompt directly.
History - Chronological feed of all agent activity: PR reviews, alert investigations, and chat conversations. Click any entry to see the full conversation and reasoning.
Chat - WebSocket-based conversation with the agent. Persists across page refreshes. Responses render full markdown - tables, code blocks, inline formatting - so the agent can present structured data clearly. Responses also show which tools were used (k8s_get_pods, github_list_prs, etc).
Memories - View everything the agent has learned. Each memory is categorized (issue, fix, preference, knowledge, config) and deletable if incorrect.
Skills - A dedicated page for managing the optional skills system. Each skill has a toggle to enable or disable it. When a skill is enabled, its tools become available to the agent immediately - no restart needed. Currently available: Prometheus, Loki, and Flux CD.
Settings - Configure everything without restarting:
- Kill switch to disable/enable the agent
- 4-tier PR mode (Comment Only, Auto-Merge Patch, Auto-Merge Minor, Fully Autonomous)
- API key management
- Per-agent model selection with descriptions of what each agent does, including Deep Review model
- Skills configuration (enable/disable Prometheus, Loki, Flux CD)
- Customizable system prompts (cluster context shared across all agents, plus per-agent instructions)
- Alert cooldown and PR check intervals
Start with comment-only mode. Let the agent review PRs and post comments before enabling auto-merge. This builds trust and lets you see how it reasons about changes.
Teach it through conversation. The memory system means you can correct the agent once and it remembers. When it suggested an unnecessary nodeSelector, I explained why PV nodeAffinity handles it automatically. It extracted that as a memory and won’t make the same mistake again.
Cheap models for cheap tasks. Haiku is ~60x cheaper than Opus per token. PR reviews don’t need the most powerful model - reading a diff and checking labels is mechanical work. Save the expensive models for tasks that actually need reasoning.
Code-level safety, not prompt-level. System prompts can be ignored or overridden through creative prompting. The guardrails that matter are in Python: hard-coded protected branches, path allowlists, namespace blocklists. These cannot be bypassed regardless of what the LLM is asked to do.
The kill switch is essential. If the agent starts doing something unexpected, you need to stop it immediately - not wait for the current operation to finish, not hope the cooldown kicks in. One button to disable everything.
The Anthropic API costs for a home lab agent are modest. Haiku handles PR reviews and alert triage, Sonnet handles fixes and chat, and Opus is reserved exclusively for deep review of high-risk PRs in Fully Autonomous mode. Since most PRs are routine Renovate bumps that never reach Opus, the expensive model barely gets used. A typical week costs a few dollars. The PR monitor checks every 30 minutes but only calls Claude when there’s a new PR to review. The alert subscriber’s two-stage pipeline helps too - most alerts get triaged by Haiku alone and never escalate to Sonnet.
The agent is functional but there’s room to grow:
- Real-time flow highlighting - Light up the dashboard flow diagram in real time as each step executes during a PR review or alert investigation. Right now the visualization is static; it would be much more useful to see work moving through the pipeline as it happens.
- Cost tracking dashboard - Break down API spend by agent, model, and task type. I have a rough sense of the weekly cost, but detailed tracking would help tune which models handle which tasks.
- Authentik SSO - Protect the web UI with forward auth once SSO configuration is complete. Right now it’s only accessible on the internal network, but proper authentication would be better.
- Volsync backup monitoring - Alert when backups fail or fall behind schedule.
The home-ops-agent is open source and designed to work with any Flux-based Kubernetes cluster that has Prometheus, Loki, and ntfy.
- Source code: github.com/MarkNygaard/home-ops-agent
- Cluster manifests: github.com/MarkNygaard/home-ops
The setup requires:
- A Kubernetes cluster with CloudNativePG (PostgreSQL)
- An ntfy server for alert subscriptions
- An Anthropic API key
- A GitHub personal access token - fine-grained (if using your own account, scoped to the repo) or classic with repo scope (if using a dedicated bot account, since fine-grained tokens can only access repos owned by the token creator)
All configuration happens through the web UI after deployment - system prompts, models, intervals, and your cluster context. No hardcoded values to change in the source code.